Record Triggered Automation – Key Takeaways:
- Preferential Automation Solutions: Flow and Apex emerge as the top choices for no-code and pro-code solutions, respectively, for triggered automation within the platform.
- Optimized Field Updates: Avoid using Workflow Rules and Process Builder for same-record field updates. Instead, opt for before-save flow triggers for better performance.
- Use Case Implementation: Whenever feasible, implement use cases in after-save flow triggers, except for same-record field updates, which should utilize before-save flow triggers.
- Batch Processing and Complexity: Utilize Apex for high-performance batch processing needs or complex implementation logic.
- Automation Organization: While not necessary to consolidate all automation into a single “mega flow” per object, consider organizing and maintaining automation for long-term benefits.
Additional Insights:
- Tool Suitability: Choose the automation tool based on team capabilities and cost-effectiveness.
- Transition from Process Builder & Workflow: While Process Builder and Workflow Rules may continue to be used, transitioning towards Flow is recommended for better architecture and functionality.
- Performance Optimization: Before-save flow triggers are significantly faster for same-record field updates compared to after-save triggers, resulting in notable performance improvements.
- Functional Considerations: Before-save flow triggers offer limited functionality but are optimized for performance, supporting essential operations efficiently.
By adhering to these takeaways and insights, organizations can streamline their automation processes and enhance overall efficiency within the Salesforce platform.
High-Performance Batch Processing
- Before-Save Flow Trigger: Not Ideal
- After-Save Flow Trigger: Not Ideal
- After-Save Flow Trigger + Apex: Not Ideal
- Apex Triggers: Available
For intricate batch processing requiring high performance and complex logic evaluation, Apex stands out with its configurable nature and robust debugging capabilities. Here’s why Apex is recommended for such scenarios:
- Complex Logic Evaluation: Apex excels in defining and assessing intricate logical expressions or formulas, which may not perform optimally in Flow due to sporadic performance issues, especially in batch scenarios where formulas are processed serially during runtime.
- List Processing: Apex enables efficient processing of complex lists, such as loading and transforming data from large record sets or performing nested loops, functionalities that might be challenging to achieve in Flow due to limited list processing capabilities.
- Map-like or Set-like Functionalities: Apex supports data structures like Maps, whereas Flow lacks native support for the Map datatype. Additionally, Apex invocable actions can pass Apex objects with Map member variables to Flow, albeit with limitations.
- Transaction Savepoints: Unlike Flow triggers, Apex triggers support transaction savepoints, providing flexibility in managing transactions and ensuring data integrity.
While before-save flow triggers might not match the performance of Apex triggers in simplistic speed comparisons, their overhead impact is mitigated within broader transactions. Before-save flow triggers still offer significant performance advantages over Workflow Rules, making them suitable for most non-complex batch scenarios, especially for same-record field updates.
For batch processing that doesn’t require immediate execution during the initial transaction, Flow provides some capabilities, albeit less feature-rich compared to Apex. Scheduled Flows and Scheduled Paths in record-triggered flows offer options for batch operations, albeit with certain limitations. However, for extensive batch processing needs, Apex remains the preferred choice due to its flexibility and performance capabilities.
Cross-Object CRUD
- Before-Save Flow Trigger: Not Available
- After-Save Flow Trigger: Available
- After-Save Flow Trigger + Apex: Available
- Apex Triggers: Available
Performing CRUD operations on different records necessitates database operations, making Apex triggers the go-to option for such cross-object operations. While Flow triggers support cross-object CRUD post-save, they lack support in the before-save context.
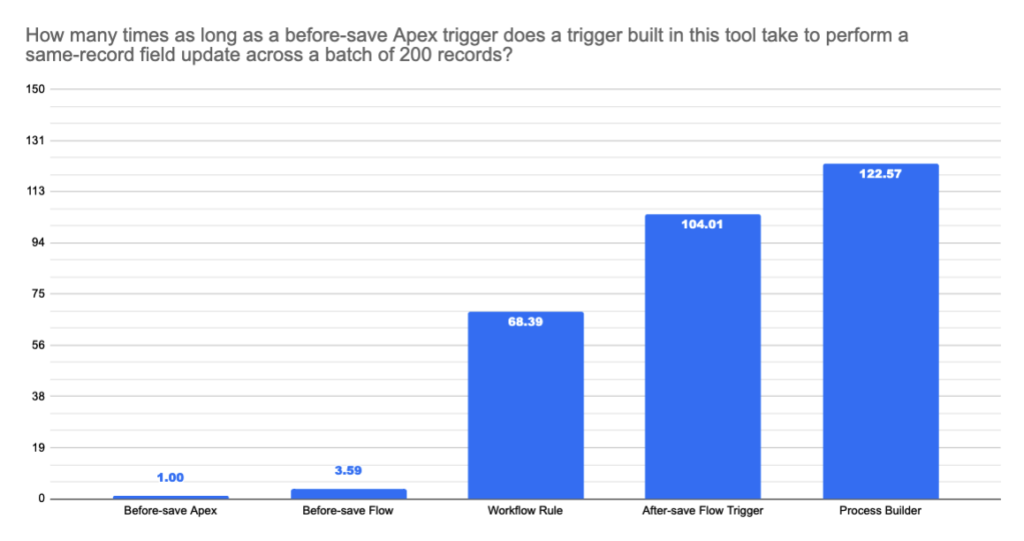
Apex outperforms Flow in raw database operation speed, ensuring quicker preparation, execution, and processing of database calls. However, optimizing user implementations, such as consolidating multiple DML statements, often yields more significant performance improvements than solely focusing on lower-level operations.
Efficiently managing DML operations and minimizing unnecessary database transactions are crucial for optimizing performance. Strategies like consolidating DML operations, using temporary record variables, and adhering to design standards aid in enhancing performance and maintaining data integrity across complex use cases.
Complex List Processing
- Before-Save Flow Trigger: Not Available
- After-Save Flow Trigger: Not Ideal
- After-Save Flow Trigger + Apex: Available
- Apex Triggers: Available
Flow presents limitations in list processing capabilities, hindering tasks like in-place data transforms, sorts, and filters, which are more efficiently achieved in Apex. Flow’s basic list processing operations and serial execution of loops contribute to challenges in handling complex lists effectively.
Extending flows with invocable Apex allows leveraging Apex’s robust list processing functionalities while retaining the usability of Flow for business-facing users. Apex developers can create efficient, modular list processing methods, making them accessible to Flow users through invocable actions.
When implementing invocable Apex methods, ensuring proper bulkification and handling multiple invocations in a batch scenario is essential. Leveraging generic sObject inputs and dynamic Apex facilitates reusable and elegant implementations across multiple triggers and sObjects.
While Flow has introduced some list processing capabilities, it still lags behind Apex in functionality, emphasizing the continued relevance of Apex for complex list processing tasks.
Asynchronous Processing
- Before-Save Flow Trigger: Not Available
- After-Save Flow Trigger: Available
- After-Save Flow Trigger + Apex: Available
- Apex Triggers: Available
Asynchronous processing offers flexibility in executing logic outside the initial transaction context, providing benefits like minimal database transactions and consistent rollbacks. Both Flow and Apex offer solutions for asynchronous processing, catering to use cases requiring separate transactions, external callouts, or prolonged processing times.
Flow’s After-Save Flow Trigger and Apex triggers support asynchronous processing, enabling the execution of logic independently from the initial transaction. While Flow offers a low-code solution through the Run Asynchronously path, Apex provides more control and customization options, especially regarding callouts and error handling.
When choosing between Flow and Apex for asynchronous processing, consider factors like control over callouts, error handling customization, and the complexity of the solution. Apex’s more extensive error handling capabilities and direct control over callouts may be advantageous for complex scenarios requiring meticulous error management.
Testing asynchronous solutions, particularly those involving callouts, necessitates careful consideration of error handling and edge cases. Apex’s advanced error handling features and flexibility in managing callouts make it suitable for handling complex scenarios effectively.
In summary, both Flow and Apex offer viable options for asynchronous processing, with the choice depending on factors like control requirements, error handling preferences, and the complexity of the solution.
Record Triggered Automation
Exploring Other Solutions
In the realm of low-code administration, administrators have historically employed various methods, often considered “hacks,” to achieve asynchronous processing. One such method involved setting up time-based workflows in Workflow Rules, scheduled actions in Process Builder, or Scheduled Paths in Flow to run immediately after a trigger execution. While effective, these approaches had their limitations. The introduction of dedicated paths, like the Run Asynchronously path in Flow, offers distinct advantages over these makeshift solutions.
The “zero-wait pause” technique, another common workaround, entailed adding a Pause element with a zero-minute wait time through an autolaunched subflow, triggered by Process Builder. Although this method effectively separated transactions, its scalability and performance were compromised, leading to potential issues with flow interview limits and performance degradation over time. Consequently, it’s not recommended, especially for subflows called from record-triggered flows.
Data Transfer and State Management Between Processes
An enticing aspect of the “zero-wait pause” approach was the perceived ability to maintain a stateful relationship between synchronous and asynchronous processing. However, this method contradicts the underlying principles of asynchronous processing, which aim for flexibility and performance control by separating processes. While flow variables may persist before and after the pause, relying on them for extended periods risks data inconsistency. To ensure data integrity, particularly across independent processes, it’s advisable to store relevant information in persistent storage, such as custom fields on the triggering record.
Summary
Asynchronous processing introduces complexities in designing record-triggered automation, especially concerning external callouts or state persistence between processes. While the Run Asynchronously path in Flow addresses many low-code requirements, scenarios involving custom errors or configurable retries may necessitate Apex. It’s crucial to consider the specific needs of your organization and weigh the benefits of each solution accordingly.
Custom Validation Errors
Flow currently lacks native support for preventing DML operations or throwing custom errors, although upcoming releases are expected to address this limitation. Until then, Validation Rules and Apex triggers remain viable options for handling complex validation scenarios.
Designing Record-Triggered Automation
Designing effective record-triggered automation involves considering various best practices and organizational needs. Performance, troubleshooting, ordering, and orchestration are key aspects to address, each offering its own set of challenges and solutions. Striking a balance between consolidation and modularization of automation components is essential for long-term maintenance and scalability.
Triggered Flow Runtime Behavior
Performance analysis reveals the efficiency of before-save Flows, particularly in high-volume batch processing scenarios. While Flow triggers demonstrate impressive performance, it’s essential to evaluate each tool’s suitability based on specific use cases and organizational requirements.
Bulkification & Recursion Control
This section aims to provide a deeper understanding of how Flow interacts with Salesforce Governor limits, particularly concerning runtime bulkification and recursion control. We’ll explore how Flow impacts key Governor limits, including:
- Total number of SOQL queries issued (100)
- Total number of DML statements issued (150)
- Total number of records processed as a result of DML statements (10,000)
- Maximum CPU time on the Salesforce servers (10,000 ms)
Before delving into the intricacies of triggered Flow runtime behavior, it’s essential to establish a common mental model of the save order for context. We adopt a tree model, where each node represents a Salesforce record processed by a timestamped DML operation. Here are some foundational principles to consider:
- Each node corresponds to a single record and its associated DML operation.
- A record can be processed by multiple DML operations during a transaction.
- Bulk DML operations can process multiple records in a single operation.
- Recursion, intentional or unintentional, may result in multiple processing instances of the same record.
The root node, Node0, marks the initiation of a save operation. Save order trees are created based on user actions, such as creating records in the UI or submitting batches via the API. At runtime, these trees expand as triggers fire and additional DML operations occur. Each tree represents the cumulative set of records processed by DML in response to a top-level operation.
Considering the Governor limits, there are constraints on the total number of processed DML records and unique timestamped DML operations per transaction. Specifically:
- The total processed DML records cannot exceed 10,000.
- There can be no more than 150 unique timestamped DML operations.
Record Triggered Automation
Now, let’s revisit an example to illustrate the implications of suboptimal Flow implementations, particularly concerning cross-object processing:
Suppose a user creates several Case records, triggering DML operations. With Flow’s bulkification logic, multiple records can be processed efficiently with fewer DML statements. However, in scenarios with multiple triggers or batch operations, the cumulative impact on Governor limits becomes apparent.
To mitigate this, functional bulkification consolidates functionally similar DML nodes, reducing the number of issued statements and optimizing CPU time. Conversely, cross-batch bulkification aims to maximize DML statement sharing across save order trees.
Additionally, recursion control enhances processing efficiency by eliminating redundant subtrees, improving overall performance.
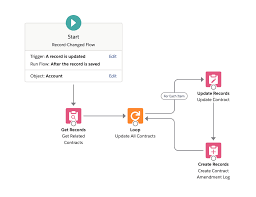
Flow Bulkification
The Flow runtime inherently implements cross-batch bulkification, managing the processing of multiple records efficiently across batches. However, functional bulkification, optimizing DML and SOQL consumption within a single batch, requires manual implementation.
Certain Flow elements contribute to DML and SOQL consumption in triggered flows:
- Create / Update / Delete Records: Each operation consumes 1 DML statement for the entire batch, excluding downstream DML triggered by object-specific triggers.
- Get Records: Each operation consumes 1 SOQL query for the entire batch.
- Action Calls: The consumption depends on the action’s implementation. The Flow runtime compiles inputs across all relevant Flow Interviews in the batch and passes them to the action for bulk processing.
- Loop: While loops themselves don’t consume DML or SOQL directly, they execute contained elements serially for each record in the batch, potentially amplifying DML and SOQL consumption.
For instance, consider a triggered Flow updating related Contracts when an Account is updated. If 200 Accounts are bulk updated, each related Contract update operation contributes to DML consumption per Contract and associated Contract Amendment Log record.
It’s strongly advised against including DML and SOQL operations within loops due to their compounding effect on resource consumption. This aligns with best practices akin to those in Apex Code development.
Flow Recursion Control
Triggered Flows adhere to recursive save behavior outlined in the Apex Developer Guide. This entails controlling recursive executions during runtime, ensuring efficient processing.
Recursion control operates within the context of a save order tree, where each node represents a record processed by a DML operation. At runtime:
- Triggers are evaluated for potential firing based on the save order.
- A trigger may fire multiple times on the same record within a transaction, but recursion control prevents redundant executions.
- Flow triggers benefit from recursion control for free, ensuring they don’t inadvertently trigger themselves on the same record.
- However, other steps in the save order do not inherently have this recursion control, necessitating careful management, especially with after-save Flow triggers performing same-record updates.
It’s crucial to consider these recursion control mechanisms when designing Flow triggers to optimize performance and avoid unintended recursive executions.
Who is Salesforce? Here is their story in their own words. From our inception, we've proudly embraced the identity of Read more

Salesforce Marketing Cloud Transactional Emails are immediate, automated, non-promotional messages crucial to business operations and customer satisfaction, such as order Read more

Salesforce has unveiled a comprehensive analytics solution tailored for wealth managers, home office professionals, and retail bankers, merging its Financial Read more

AI plays a crucial role in propensity score estimation as it can discern underlying patterns between treatments and confounding variables Read more




