
An Independent Analysis of GPT-4o’s Classification Abilities
Article by Lars Wilk
OpenAI’s recent unveiling of GPT-4o marks a significant advancement in AI language models, transforming how we interact with them. The most impressive feature is the live interaction capability with ChatGPT, allowing for seamless conversational interruptions. GPT-4o GPT4 and Gemini 1.5
Despite a few hiccups during the live demo, the achievements of the OpenAI team are undeniably impressive. Best of all, immediately after the demo, OpenAI granted access to the GPT-4o API.
In this article, I will present my independent analysis, comparing the classification abilities of GPT-4o with GPT-4, Google’s Gemini, and Unicorn models using an English dataset I created. Which of these models is the strongest in understanding English?
What’s New with GPT-4o?
GPT-4o introduces the concept of an Omni model, designed to seamlessly process text, audio, and video. OpenAI aims to democratize GPT-4 level intelligence, making it accessible even to free users. Enhanced quality and speed across more than 50 languages, combined with a lower price point, promise a more inclusive and globally accessible AI experience. Additionally, paid subscribers will benefit from five times the capacity compared to non-paid users. OpenAI also announced a desktop version of ChatGPT to facilitate real-time reasoning across audio, vision, and text interfaces.
How to Use the GPT-4o API
The new GPT-4o model follows the existing chat-completion API, ensuring backward compatibility and ease of use:
pythonCopy codefrom openai import AsyncOpenAI
OPENAI_API_KEY = "<your-api-key>"
def openai_chat_resolve(response: dict, strip_tokens=None) -> str:
if strip_tokens is None:
strip_tokens = []
if response and response.choices and len(response.choices) > 0:
content = response.choices[0].message.content.strip()
if content:
for token in strip_tokens:
content = content.replace(token, '')
return content
raise Exception(f'Cannot resolve response: {response}')
async def openai_chat_request(prompt: str, model_name: str, temperature=0.0):
message = {'role': 'user', 'content': prompt}
client = AsyncOpenAI(api_key=OPENAI_API_KEY)
return await client.chat.completions.create(
model=model_name,
messages=[message],
temperature=temperature,
)
openai_chat_request(prompt="Hello!", model_name="gpt-4o-2024-05-13")
GPT-4o is also accessible via the ChatGPT interface.
Official Evaluation GPT-4o GPT4 and Gemini 1.5
OpenAI’s blog post includes evaluation scores on known datasets such as MMLU and HumanEval, showcasing GPT-4o’s state-of-the-art performance. However, many models claim superior performance on open datasets, often due to overfitting. Independent analyses using lesser-known datasets are crucial for a realistic assessment.
My Evaluation Dataset
I created a dataset of 200 sentences categorized under 50 topics, designed to challenge classification tasks. The dataset is manually labeled in English. For this evaluation, I used only the English version to avoid potential biases from using the same language model for dataset creation and topic prediction. You can check out the dataset here.
Performance Results
I evaluated the following models:
- GPT-4o: gpt-4o-2024-05-13
- GPT-4: gpt-4-0613
- GPT-4-Turbo: gpt-4-turbo-2024-04-09
- Gemini 1.5 Pro: gemini-1.5-pro-preview-0409
- Gemini 1.0: gemini-1.0-pro-002
- Palm 2 Unicorn: text-unicorn@001
The task was to match each sentence with the correct topic, calculating an accuracy score and error rate for each model. A lower error rate indicates better performance.
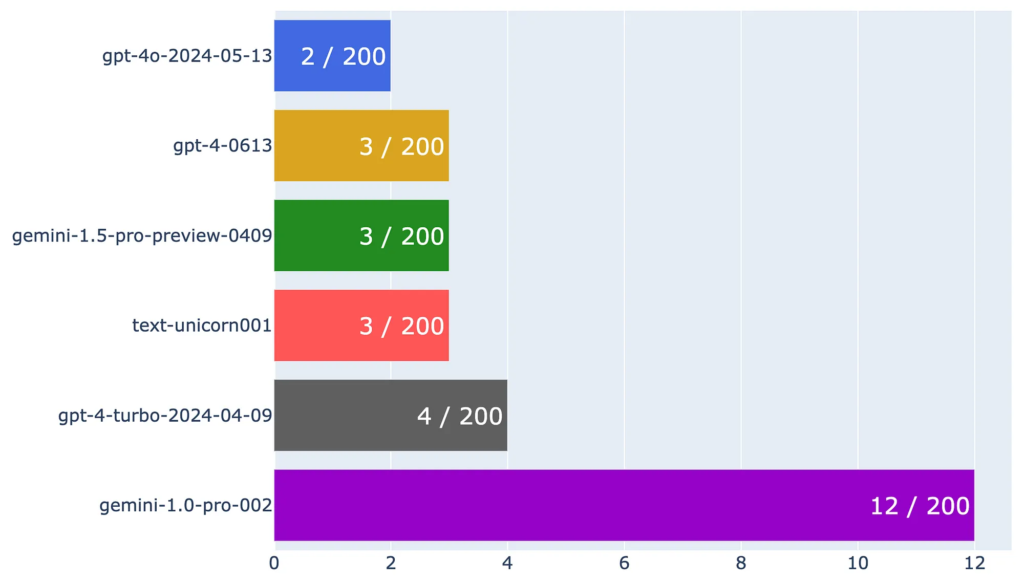
Conclusion
This analysis using a uniquely crafted English dataset reveals insights into the state-of-the-art capabilities of these advanced language models. GPT-4o stands out with the lowest error rate, affirming OpenAI’s performance claims. Independent evaluations with diverse datasets are essential for a clearer picture of a model’s practical effectiveness beyond standardized benchmarks.
Note that the dataset is fairly small, and results may vary with different datasets. This evaluation was conducted using the English dataset only; a multilingual comparison will be conducted at a later time.
Who is Salesforce? Here is their story in their own words. From our inception, we've proudly embraced the identity of Read more

Salesforce has unveiled a comprehensive analytics solution tailored for wealth managers, home office professionals, and retail bankers, merging its Financial Read more

AI plays a crucial role in propensity score estimation as it can discern underlying patterns between treatments and confounding variables Read more
Salesforce Technology Services Integrator - Tectonic has successfully delivered Salesforce in a variety of industries including Public Sector, Hospitality, Manufacturing, Read more






