A comprehensive study has been conducted on advanced retrieval augmented generation techniques and algorithms, systematically organizing various approaches. This insight includes a collection of links referencing various implementations and studies mentioned in the author’s knowledge base.
If you’re familiar with the RAG concept, skip to the Advanced RAG section.
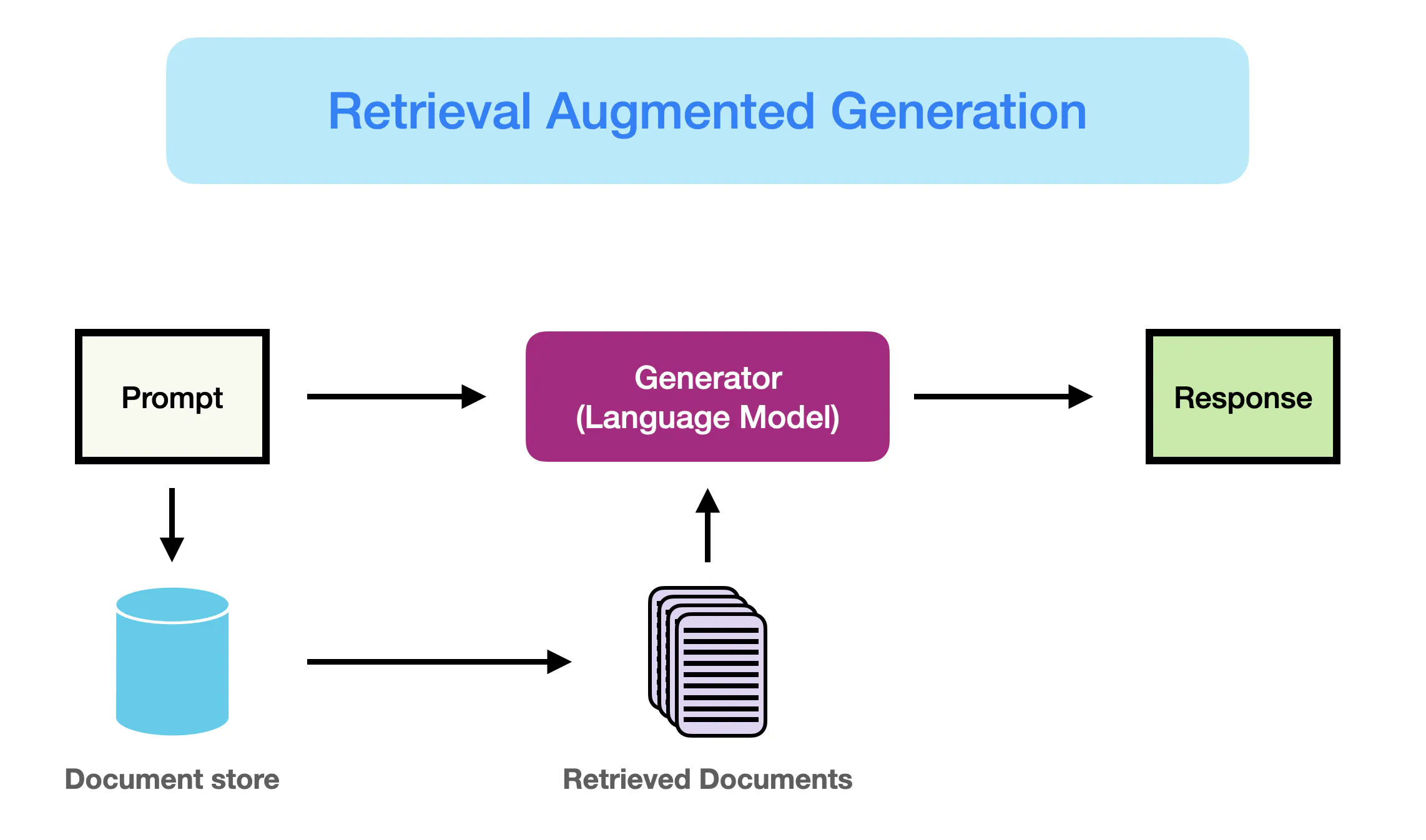
Retrieval Augmented Generation, known as RAG, equips Large Language Models (LLMs) with retrieved information from a data source to ground their generated answers. Essentially, RAG combines Search with LLM prompting, where the model is asked to answer a query provided with information retrieved by a search algorithm as context. Both the query and the retrieved context are injected into the prompt sent to the LLM.
RAG emerged as the most popular architecture for LLM-based systems in 2023, with numerous products built almost exclusively on RAG. These range from Question Answering services that combine web search engines with LLMs to hundreds of apps allowing users to interact with their data.
Even the vector search domain experienced a surge in interest, despite embedding-based search engines being developed as early as 2019. Vector database startups such as Chroma, Weavaite.io, and Pinecone have leveraged existing open-source search indices, mainly Faiss and Nmslib, and added extra storage for input texts and other tooling.
Two prominent open-source libraries for LLM-based pipelines and applications are LangChain and LlamaIndex, both founded within a month of each other in October and November 2022, respectively. These were inspired by the launch of ChatGPT and gained massive adoption in 2023.
The purpose of this Tectonic insight is to systemize key advanced RAG techniques with references to their implementations, mostly in LlamaIndex, to facilitate other developers’ exploration of the technology.
The problem addressed is that most tutorials focus on individual techniques, explaining in detail how to implement them, rather than providing an overview of the available tools.
Naive RAG
The starting point of the RAG pipeline described in this article is a corpus of text documents. The process begins with splitting the texts into chunks, followed by embedding these chunks into vectors using a Transformer Encoder model. These vectors are then indexed, and a prompt is created for an LLM to answer the user’s query given the context retrieved during the search step.
In runtime, the user’s query is vectorized with the same Encoder model, and a search is executed against the index. The top-k results are retrieved, corresponding text chunks are fetched from the database, and they are fed into the LLM prompt as context.
An overview of advanced RAG techniques, illustrated with core steps and algorithms.
- Chunking & Vectorization Firstly, an index of vectors representing document contents is created, and during runtime, a search is conducted for the least cosine distance between these vectors and the query vector.
1.1 Chunking Texts are split into chunks of a certain size without losing their meaning. Various text splitter implementations capable of this task exist.
1.2 Vectorization A model is chosen to embed the chunks, with options including search-optimized models like bge-large or E5 embeddings family.
- Search Index The crucial part of the RAG pipeline is the search index, which stores the vectorized content obtained in the previous step. Different implementations such as Faiss, Nmslib, or Annoy are used for efficient retrieval on large datasets.
2.1 Vector Store Index Various indices are supported, including flat indices and vector indices like Faiss, Nmslib, or Annoy.
2.2 Hierarchical Indices Efficient search within large databases is facilitated by creating two indices: one composed of summaries and another composed of document chunks.
2.3 Hypothetical Questions and HyDE An alternative approach involves asking an LLM to generate a question for each chunk, embedding these questions in vectors, and performing query search against this index of question vectors.
2.4 Context Enrichment Smaller chunks are retrieved for better search quality, with surrounding context added for the LLM to reason upon.
2.4.1 Sentence Window Retrieval Each sentence in a document is embedded separately to provide accurate search results.
2.4.2 Auto-merging Retriever Documents are split into smaller child chunks referring to larger parent chunks to enhance context retrieval.
2.5 Fusion Retrieval or Hybrid Search Keyword-based old school search algorithms are combined with modern semantic or vector search to improve retrieval results.
- Reranking & Filtering Retrieved results are refined through filtering, reranking, or transformation before being fed to the LLM.
- Query Transformations LLMs are used to modify user input to improve retrieval quality, employing techniques such as query decomposition, step-back prompting, and query rewriting.
- Chat Engine Context compression techniques are used to support follow-up questions, anaphora, or arbitrary user commands relating to previous dialogue context.
- Query Routing LLM-powered decision making determines whether to summarize, perform a search, or try different routes given the user query.
- Agents in RAG Agents provide LLMs with a set of tools and tasks to complete, enabling complex logic involving LLM reasoning within the RAG pipeline.
- Response Synthesizer The final step involves generating an answer based on the retrieved context and the initial user query, with options including iterative refinement, summarization, or generating multiple answers.
Encoder and LLM Fine-tuning Fine-tuning of Transformer Encoders or LLMs can further enhance the RAG pipeline’s performance, improving context retrieval quality or answer relevance.
Evaluation Various frameworks exist for evaluating RAG systems, with metrics focusing on retrieved context relevance, answer groundedness, and overall answer relevance.
The next big thing about building a nice RAG system that can work more than once for a single query is the chat logic, taking into account the dialogue context, same as in the classic chat bots in the pre-LLM era.
This is needed to support follow up questions, anaphora, or arbitrary user commands relating to the previous dialogue context. It is solved by query compression technique, taking chat context into account along with the user query.
Query routing is the step of LLM-powered decision making upon what to do next given the user query — the options usually are to summarise, to perform search against some data index or to try a number of different routes and then to synthesise their output in a single answer.
Query routers are also used to select an index, or, broader, data store, where to send user query — either you have multiple sources of data, for example, a classic vector store and a graph database or a relational DB, or you have an hierarchy of indices — for a multi-document storage a pretty classic case would be an index of summaries and another index of document chunks vectors for example.
This insight aims to provide an overview of core algorithmic approaches to RAG, offering insights into techniques and technologies developed in 2023. It emphasizes the importance of speed in RAG systems and suggests potential future directions, including exploration of web search-based RAG and advancements in agentic architectures.
Who is Salesforce? Here is their story in their own words. From our inception, we've proudly embraced the identity of Read more

Salesforce has unveiled a comprehensive analytics solution tailored for wealth managers, home office professionals, and retail bankers, merging its Financial Read more

AI plays a crucial role in propensity score estimation as it can discern underlying patterns between treatments and confounding variables Read more
Salesforce Technology Services Integrator - Tectonic has successfully delivered Salesforce in a variety of industries including Public Sector, Hospitality, Manufacturing, Read more







