Enhancing Retrieval-Augmented Generation (RAG) Systems with Topic-Based Document Segmentation
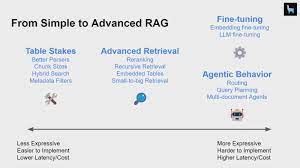
Dividing large documents into smaller, meaningful parts is crucial for the performance of Retrieval-Augmented Generation (RAG) systems. RAG Chunking Method. These systems benefit from frameworks that offer multiple document-splitting options. This Tectonic insight introduces an innovative approach that identifies topic changes using sentence embeddings, improving the subdivision process to create coherent topic-based sections.
RAG Systems: An Overview
A Retrieval-Augmented Generation (RAG) system combines retrieval-based and generation-based models to enhance output quality and relevance. It first retrieves relevant information from a large dataset based on an input query, then uses a transformer-based language model to generate a coherent and contextually appropriate response. This hybrid approach is particularly effective in complex or knowledge-intensive tasks.
Standard Document Splitting Options
Before diving into the new approach, let’s explore some standard document splitting methods using the LangChain framework, known for its robust support of various natural language processing (NLP) tasks.
LangChain Framework: LangChain assists developers in applying large language models across NLP tasks, including document splitting. Here are key splitting methods available:
- Recursive Character Text Splitter: Splits documents by recursively dividing the text based on characters, maintaining each chunk below a specified length.pythonCopy code
from langchain.text_splitter import RecursiveCharacterTextSplitter text = "Your long document text goes here..." splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50) chunks = splitter.split_text(text) for chunk in chunks: print(chunk) - Token Splitter: Splits documents using tokens, ideal for language models with token limits.pythonCopy code
from langchain.text_splitter import TokenSplitter text = "Your long document text goes here..." splitter = TokenSplitter(max_tokens=512) chunks = splitter.split_text(text) for chunk in chunks: print(chunk) - Sentence Splitter: Splits documents at sentence boundaries, maintaining the contextual integrity of the text.pythonCopy code
from langchain.text_splitter import SentenceSplitter text = "Your long document text goes here..." splitter = SentenceSplitter(max_length=5) chunks = splitter.split_text(text) for chunk in chunks: print(chunk) - Regex Splitter: Uses regular expressions for custom split points.pythonCopy code
from langchain.text_splitter import RegexSplitter text = "Your long document text goes here..." splitter = RegexSplitter(pattern=r'nn+') chunks = splitter.split_text(text) for chunk in chunks: print(chunk) - Markdown Splitter: Splits markdown documents based on markdown-specific elements.pythonCopy code
from langchain.text_splitter import MarkdownSplitter text = "Your long markdown document goes here..." splitter = MarkdownSplitter() chunks = splitter.split_text(text) for chunk in chunks: print(chunk)
Introducing a New Approach: Topic-Based Segmentation
Segmenting large-scale documents into coherent topic-based sections poses significant challenges. Traditional methods often fail to detect subtle topic shifts accurately. This innovative approach, presented at the International Conference on Artificial Intelligence, Computer, Data Sciences, and Applications (ACDSA 2024), addresses this issue using sentence embeddings.
The Core Challenge
Large documents often contain multiple topics. Conventional segmentation techniques struggle to identify precise topic transitions, leading to fragmented or overlapping sections. This method leverages Sentence-BERT (SBERT) to generate embeddings for individual sentences, which reflect changes in the vector space as topics shift.
Approach Breakdown
1. Using Sentence Embeddings:
- Generating Embeddings: SBERT creates dense vector representations of sentences, encapsulating their semantic content.
- Similarity Calculation: Measures similarity using cosine similarity or other distance measures to detect topic coherence.
2. Calculating Gap Scores:
- Defining a Parameter n: Specifies the number of sentences to compare (e.g., n=2).
- Computing Cosine Similarity: Calculates similarity between embeddings of sentence sequences, termed ‘gap scores.’
3. Smoothing:
- Addressing Noise: Applies a smoothing algorithm to average gap scores over a defined window, reducing noise.
- Choosing the Window Size k: Balances detailed transitions with computational efficiency.
4. Boundary Detection:
- Identifying Local Minima: Analyzes smoothed gap scores to find topic transitions.
- Setting a Threshold c: Uses a threshold to determine significant segmentation points.
5. Clustering Segments:
- Handling Repeated Topics: Clusters similar segments to reduce redundancy and enhance coherence.
Algorithm Pseudocode
Gap Score Calculation:
pythonCopy code# Example pseudocode for gap score calculation
def calculate_gap_scores(sentences, n):
embeddings = [sbert.encode(sentence) for sentence in sentences]
gap_scores = []
for i in range(len(sentences) - n):
before = embeddings[i:i+n]
after = embeddings[i+n:i+2*n]
score = cosine_similarity(before, after)
gap_scores.append(score)
return gap_scores
Gap Score Smoothing:
pythonCopy code# Example pseudocode for smoothing gap scores
def smooth_gap_scores(gap_scores, k):
smoothed_scores = []
for i in range(len(gap_scores)):
start = max(0, i - k)
end = min(len(gap_scores), i + k + 1)
smoothed_score = sum(gap_scores[start:end]) / (end - start)
smoothed_scores.append(smoothed_score)
return smoothed_scores
Boundary Detection:
pythonCopy code# Example pseudocode for boundary detection
def detect_boundaries(smoothed_scores, c):
boundaries = []
mean_score = sum(smoothed_scores) / len(smoothed_scores)
std_dev = (sum((x - mean_score) ** 2 for x in smoothed_scores) / len(smoothed_scores)) ** 0.5
for i, score in enumerate(smoothed_scores):
if score < mean_score - c * std_dev:
boundaries.append(i)
return boundaries
Future Directions
Potential areas for further research include:
- Automatic Parameter Optimization: Using machine learning to adjust parameters dynamically.
- Extensive Dataset Trials: Testing the method on diverse datasets.
- Real-Time Segmentation: Exploring real-time applications for dynamic documents.
- Model Improvements: Integrating newer transformer models.
- Multilingual Segmentation: Applying the method to different languages using multilingual SBERT.
- Hierarchical Segmentation: Investigating segmentation at multiple levels.
- User Interface Development: Creating interactive tools for easier segmentation adjustment.
- Integration with NLP Tasks: Combining the algorithm with other natural language processing tasks.
Conclusion
This method combines traditional principles with advanced sentence embeddings, leveraging SBERT and sophisticated smoothing and clustering techniques. This approach offers a robust and efficient solution for accurate topic modeling in large documents, enhancing the performance of RAG systems by providing coherent and contextually relevant text sections.
Who is Salesforce? Here is their story in their own words. From our inception, we've proudly embraced the identity of Read more

Salesforce has unveiled a comprehensive analytics solution tailored for wealth managers, home office professionals, and retail bankers, merging its Financial Read more

AI plays a crucial role in propensity score estimation as it can discern underlying patterns between treatments and confounding variables Read more
Salesforce Technology Services Integrator - Tectonic has successfully delivered Salesforce in a variety of industries including Public Sector, Hospitality, Manufacturing, Read more







