Breakthroughs in Language Models: From Word2Vec to Transformers
Language models have rapidly evolved since 2018, driven by advancements in neural network architectures for text representation. This journey began with Word2Vec and N-Grams in 2013, followed by the emergence of Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks in 2014. The pivotal moment came with the introduction of the Attention Mechanism, which paved the way for large pre-trained models and transformers. BERT and GPT.
From Word Embedding to Transformers
The story of language models begins with word embedding.
What is Word Embedding? Word embedding is a technique in natural language processing (NLP) where words are represented as vectors in a continuous vector space. These vectors capture semantic meanings, allowing words with similar meanings to have similar representations. For instance, in a word embedding model, “king” and “queen” would have vectors close to each other, reflecting their related meanings. Similarly, “car” and “truck” would be near each other, as would “cat” and “dog.” However, “car” and “dog” would not have close vectors due to their different meanings.
A notable example of word embedding is Word2Vec.
Word2Vec: Neural Network Model Using N-Grams Introduced by Mahajan, Patil, and Sankar in 2013, Word2Vec is a neural network model that uses n-grams by training on context windows of words. It has two main approaches:
- Continuous Bag of Words (CBOW): Predicts a target word based on its surrounding context (n-grams). For example, given the context “the cat sat on the,” CBOW predicts the word “mat.”
- Skip-gram: Predicts the surrounding words given a target word. For example, given the word “cat,” Skip-gram predicts the context words “the,” “sat,” “on,” and “the.”
Both methods help capture semantic relationships, providing meaningful word embeddings that facilitate various NLP tasks like sentiment analysis and machine translation.
Recurrent Neural Networks (RNNs) RNNs are designed for sequential data, processing inputs sequentially and maintaining a hidden state that captures information about previous inputs. This makes them suitable for tasks like time series prediction and natural language processing. The concept of RNNs can be traced back to 1925 with the Ising model, used to simulate magnetic interactions analogous to RNNs’ state transitions for sequence learning.
Long Short-Term Memory (LSTM) Networks LSTMs, introduced by Hochreiter and Schmidhuber in 1997, are a specialized type of RNN designed to overcome the limitations of standard RNNs, particularly the vanishing gradient problem. They use gates (input, output, and forget gates) to regulate information flow, enabling them to maintain long-term dependencies and remember important information over long sequences.
Comparing Word2Vec, RNNs, and LSTMs
- Purpose: Word2Vec generates dense vector representations for words based on their context. RNNs and LSTMs model and predict sequences.
- Architecture: Word2Vec employs shallow, two-layer neural networks. RNNs and LSTMs have deeper architectures designed for sequential data.
- Output: Word2Vec outputs fixed-size vectors for words. RNNs and LSTMs output sequences of vectors, suitable for tasks requiring context understanding over time.
- Memory Handling: LSTMs, unlike standard RNNs and Word2Vec, can manage long-term dependencies due to their gating mechanisms.
The Attention Mechanism and Its Impact
The attention mechanism, introduced in the paper “Attention Is All You Need” by Vaswani et al., is a key component in transformers and large pre-trained language models. It allows models to focus on specific parts of the input sequence when generating output, assigning different weights to different words or tokens, and enabling the model to prioritize important information and handle long-range dependencies effectively.
Transformers: Revolutionizing Language Models Transformers use self-attention mechanisms to process input sequences in parallel, capturing contextual relationships between all tokens in a sequence simultaneously. This improves handling of long-term dependencies and reduces training time. The self-attention mechanism identifies the relevance of each token to every other token within the input sequence, enhancing the model’s ability to understand context.
Large Pre-Trained Language Models: BERT and GPT
Both BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) are based on the transformer architecture.
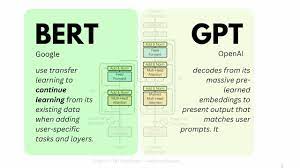
BERT Introduced by Google in 2018, BERT pre-trains deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. This enables BERT to create state-of-the-art models for tasks like question answering and language inference without substantial task-specific architecture modifications.
GPT Developed by OpenAI, GPT models are known for generating human-like text. They are pre-trained on large corpora of text and fine-tuned for specific tasks. GPT is majorly generative and unidirectional, focusing on creating new text content like poems, code, scripts, and more.
Major Differences Between BERT and GPT
- BERT: Bidirectional, excels in understanding context, used for tasks like question answering and language inference.
- GPT: Unidirectional, excels in generating text, used for creating content like poems, scripts, and more.
In conclusion, while both BERT and GPT are based on the transformer architecture and are pre-trained on large corpora of text, they serve different purposes and excel in different tasks. The advancements from Word2Vec to transformers highlight the rapid evolution of language models, enabling increasingly sophisticated NLP applications.
Who is Salesforce? Here is their story in their own words. From our inception, we've proudly embraced the identity of Read more

Salesforce has unveiled a comprehensive analytics solution tailored for wealth managers, home office professionals, and retail bankers, merging its Financial Read more

AI plays a crucial role in propensity score estimation as it can discern underlying patterns between treatments and confounding variables Read more
Salesforce Technology Services Integrator - Tectonic has successfully delivered Salesforce in a variety of industries including Public Sector, Hospitality, Manufacturing, Read more







