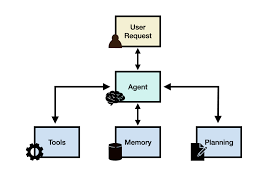
Reward-Guided Speculative Decoding
Salesforce AI Research Unveils Reward-Guided Speculative Decoding (RSD): A Breakthrough in Large Language Model (LLM) Inference Efficiency Addressing the Computational Challenges of LLMs The rapid scaling of large language models (LLMs) has led to remarkable advancements in natural language understanding and reasoning. However, inference—the process of generating responses one token at a time—remains a major computational bottleneck. As LLMs grow in size and complexity, latency and energy consumption increase, posing challenges for real-world applications that demand cost efficiency, speed, and scalability. Traditional decoding methods, such as greedy and beam search, require repeated evaluations of large models, leading to significant computational overhead. Even parallel decoding techniques struggle to balance efficiency with output quality. These challenges have driven research into hybrid approaches that combine lightweight models with more powerful ones, optimizing speed without sacrificing performance. Introducing Reward-Guided Speculative Decoding (RSD) Salesforce AI Research introduces Reward-Guided Speculative Decoding (RSD), a novel framework designed to enhance LLM inference efficiency. RSD employs a dual-model strategy: Unlike traditional speculative decoding, which enforces strict token matching between draft and target models, RSD introduces a controlled bias that prioritizes high-reward outputs—tokens deemed more accurate or contextually relevant. This strategic bias significantly reduces unnecessary computations. RSD’s mathematically derived threshold mechanism dictates when the target model should intervene. By dynamically blending outputs from both models based on a reward function, RSD accelerates inference while maintaining or even enhancing response quality. This innovation addresses the inefficiencies inherent in sequential token generation for LLMs. Technical Insights and Benefits of RSD RSD integrates two models in a sequential, cooperative manner: This mechanism is guided by a binary step weighting function, ensuring that only high-quality tokens bypass the target model, significantly reducing computational demands. Key Benefits: The theoretical foundation of RSD, including the probabilistic mixture distribution and adaptive acceptance criteria, provides a robust framework for real-world deployment across diverse reasoning tasks. Empirical Results: Superior Performance Across Benchmarks Experiments on challenging datasets—such as GSM8K, MATH500, OlympiadBench, and GPQA—demonstrate RSD’s effectiveness. Notably, on the MATH500 benchmark, RSD achieved 88.0% accuracy using a 72B target model and a 7B PRM, outperforming the target model’s standalone accuracy of 85.6% while reducing FLOPs by nearly 4.4×. These results highlight RSD’s potential to surpass traditional methods, including speculative decoding (SD), beam search, and Best-of-N strategies, in both speed and accuracy. A Paradigm Shift in LLM Inference Reward-Guided Speculative Decoding (RSD) represents a significant advancement in LLM inference. By intelligently combining a draft model with a powerful target model and incorporating a reward-based acceptance criterion, RSD effectively mitigates computational costs without compromising quality. This biased acceleration approach strategically bypasses expensive computations for high-reward outputs, ensuring an efficient and scalable inference process. With empirical results showcasing up to 4.4× faster performance and superior accuracy, RSD sets a new benchmark for hybrid decoding frameworks, paving the way for broader adoption in real-time AI applications. Like Related Posts Salesforce OEM AppExchange Expanding its reach beyond CRM, Salesforce.com has launched a new service called AppExchange OEM Edition, aimed at non-CRM service providers. Read more The Salesforce Story In Marc Benioff’s own words How did salesforce.com grow from a start up in a rented apartment into the world’s Read more Salesforce Jigsaw Salesforce.com, a prominent figure in cloud computing, has finalized a deal to acquire Jigsaw, a wiki-style business contact database, for Read more Service Cloud with AI-Driven Intelligence Salesforce Enhances Service Cloud with AI-Driven Intelligence Engine Data science and analytics are rapidly becoming standard features in enterprise applications, Read more