Building Scalable AI Agents
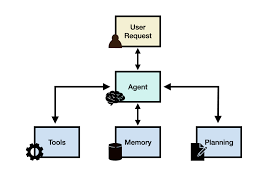
Building Scalable AI Agents: Infrastructure, Planning, and Security The key building blocks of AI agents—planning, tool integration, and memory—demand sophisticated infrastructure to function effectively in production environments. As the technology advances, several critical components have emerged as essential for successful deployments. Development Frameworks & Architecture The ecosystem for AI agent development has matured, with several key frameworks leading the way: While these frameworks offer unique features, successful agents typically share three core architectural components: Despite these strong foundations, production deployments often require customization to address high-scale workloads, security requirements, and system integrations. Planning & Execution Handling complex tasks requires advanced planning and execution flows, typically structured around: An agent’s effectiveness hinges on its ability to: ✅ Generate structured plans by intelligently combining tools and knowledge (e.g., correctly sequencing API calls for a customer refund request).✅ Validate each task step to prevent errors from compounding.✅ Optimize computational costs in long-running operations.✅ Recover from failures through dynamic replanning.✅ Apply multiple validation strategies, from structural verification to runtime testing.✅ Collaborate with other agents when consensus-based decisions improve accuracy. While multi-agent consensus models improve accuracy, they are computationally expensive. Even OpenAI finds that running parallel model instances for consensus-based responses remains cost-prohibitive, with ChatGPT Pro priced at $200/month. Running majority-vote systems for complex tasks can triple or quintuple costs, making single-agent architectures with robust planning and validation more viable for production use. Memory & Retrieval AI agents require advanced memory management to maintain context and learn from experience. Memory systems typically include: 1. Context Window 2. Working Memory (State Maintained During a Task) Key context management techniques: 3. Long-Term Memory & Knowledge Management AI agents rely on structured storage systems for persistent knowledge: Advanced Memory Capabilities Standardization efforts like Anthropic’s Model Context Protocol (MCP) are emerging to streamline memory integration, but challenges remain in balancing computational efficiency, consistency, and real-time retrieval. Security & Execution As AI agents gain autonomy, security and auditability become critical. Production deployments require multiple layers of protection: 1. Tool Access Control 2. Execution Validation 3. Secure Execution Environments 4. API Governance & Access Control 5. Monitoring & Observability 6. Audit Trails These security measures must balance flexibility, reliability, and operational control to ensure trustworthy AI-driven automation. Conclusion Building production-ready AI agents requires a carefully designed infrastructure that balances:✅ Advanced memory systems for context retention.✅ Sophisticated planning capabilities to break down tasks.✅ Secure execution environments with strong access controls. While AI agents offer immense potential, their adoption remains experimental across industries. Organizations must strategically evaluate where AI agents justify their complexity, ensuring that they provide clear, measurable benefits over traditional AI models. Like1 Related Posts Salesforce OEM AppExchange Expanding its reach beyond CRM, Salesforce.com has launched a new service called AppExchange OEM Edition, aimed at non-CRM service providers. Read more Salesforce Jigsaw Salesforce.com, a prominent figure in cloud computing, has finalized a deal to acquire Jigsaw, a wiki-style business contact database, for Read more Service Cloud with AI-Driven Intelligence Salesforce Enhances Service Cloud with AI-Driven Intelligence Engine Data science and analytics are rapidly becoming standard features in enterprise applications, Read more Health Cloud Brings Healthcare Transformation Following swiftly after last week’s successful launch of Financial Services Cloud, Salesforce has announced the second installment in its series Read more