Advanced RAG
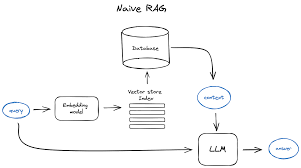
Significant Changes in Context Windows and Token Costs The first significant change in the AI world is the substantial increase in the context window size and the decrease in token costs. For example, the context window size of the largest model, Claude from Anthropic, exceeds 200,000 tokens. According to the latest news, Gemini’s context window can reach up to 10 million tokens. Under these conditions, Retrieval-Augmented Generation (RAG) may not be required for many tasks, as all necessary data can fit into the context window. This shift has been observed in several financial and analytical projects where tasks were completely solved without using a vector database as intermediate storage. The trend of reducing token costs and increasing context window sizes is likely to continue, diminishing the need for external mechanisms for large language models (LLMs). However, they remain necessary for the time being. Advanced RAG. If the context size is still insufficient, different methods of summarization and context compression have been devised. LangChain has introduced a class aimed at this: ConversationSummaryMemory. pythonCopy codellm = OpenAI(temperature=0) conversation_with_summary = ConversationChain( llm=llm, memory=ConversationSummaryMemory(llm=OpenAI()), verbose=True ) conversation_with_summary.predict(input=”Hi, what’s up?”) Knowledge Graphs As the amount of data LLMs must navigate grows, the ability to navigate this data becomes increasingly important. Without the ability to analyze the data structure and other attributes, it’s impossible to use them effectively. For example, suppose the data source is a company’s wiki with a page containing the company’s phone number, but this isn’t explicitly indicated anywhere. How does the LLM understand that this is the company’s phone number? It doesn’t, which is why standard RAG won’t provide any information about the company’s phone number (as it sees no connection). A person can understand that this is the company’s phone number from the convention of how the data is stored (i.e., from the structure or metadata). For LLMs, this problem is solved with Knowledge Graphs with metadata (also known as Knowledge Maps), which means the LLM has not only the raw data but also information about the storage structure and the connections between different data entities. This approach is also known as Graph Retrieval-Augmented Generation (GraphRAG). Graphs are excellent for representing and storing heterogeneous and interconnected information in a structured form, easily capturing complex relationships and attributes among different types of data, which vector databases struggle with. Example of a Knowledge Graph Creating a Knowledge Graph typically involves collecting and structuring data, requiring a deep understanding of both the subject area and graph modeling. This process can largely be automated with LLMs. Thanks to their understanding of language and context, LLMs can automate significant parts of the Knowledge Graph creation process. By analyzing textual data, these models can identify entities, understand their relationships, and suggest how best to represent them in a graph structure. Advanced RAG This ensemble of a vector database and a knowledge graph generally improves accuracy and often includes a search through a regular database or by keywords (e.g., Elasticsearch). Knowledge Graph Retriever Example For example, a user asks a question about the company’s phone number. If this is done in code, the entities from the question can be formatted in JSON or using with_structured_output from LangChain. These entities are then searched for in the Knowledge Graph. How this is done depends on where the graph is stored. pythonCopy codedocuments = parse_and_load_data_from_wiki_including_metadata() graph_store = NebulaGraphStore( space_name=”Company Wiki”, tags=[“entity”] ) storage_context = StorageContext.from_defaults(graph_store=graph_store) index = KnowledgeGraphIndex.from_documents( documents, max_triplets_per_chunk=2, space_name=”Company Wiki”, tags=[“entity”] ) query_engine = index.as_query_engine() response = query_engine.query(“Tell me more about our Company”) The search differs from a vector database search in that it searches for attributes and related entities, not similar vectors. Returning to the initial question, if the wiki structure was transferred to the graph correctly, the company’s phone number would be added as a related entity in the graph. The data from the graph and the vector database search are then passed to the LLM to generate a complete answer. Challenges and Solutions Access Control Access to data may not be uniform. In the same wiki, there may be roles and permissions, and not every user can see all information. This problem exists for both graph and vector database searches, requiring access management. Role-Based Access Control (RBAC), Attribute-Based Access Control (ABAC), and Relationship-Based Access Control (ReBAC) are common methods. Permissions and categories are also forms of metadata, which must be preserved at the data ingestion stage in the knowledge graph and vector database. When searching in the vector database, it is necessary to check whether the role or other access attributes match what the user has access to. Some commercial vector databases already include this functionality. Data embedded in the LLM during training relies on the LLM’s reasonableness, which is not recommended. Ingestion and Parsing Data needs to be inserted into the graph and the vector database. For the graph, the format is critical as it reflects the data structure and serves as metadata. Parsing data, especially from PDFs, can be challenging. Frameworks like LLama Parse attempt this with varying degrees of success. However, OCR or recognizing a document image can sometimes be easier. Improving Answer Advanced RAG Several approaches aim to improve answer quality beyond using knowledge graphs: Corrective Retrieval Augmented Generation (CRAG) CRAG addresses incorrect RAG results by automating correction processes. LangGraph can implement this approach, which essentially forms a state machine. Self-RAG Self-reflective RAG fine-tunes the LLM to generate self-reflection tokens in addition to regular ones, helping build a state machine for better results. HyDe HyDe (Hypothetical Document Embeddings) modifies the usual RAG retrieval process by using the LLM to generate a response and then searching the vector database with that response. This is useful when users’ questions are too abstract and require more context. These methods, including CRAG, Self-RAG, and HyDe, provide various ways to enhance the performance of LLMs and improve the quality of their answers. Like Related Posts Salesforce OEM AppExchange Expanding its reach beyond CRM, Salesforce.com has launched a new service called AppExchange OEM Edition, aimed at non-CRM




