AI Agents Connect Tool Calling and Reasoning
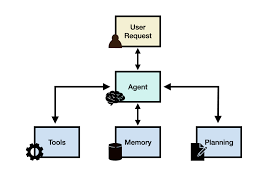
AI Agents: Bridging Tool Calling and Reasoning in Generative AI Exploring Problem Solving and Tool-Driven Decision Making in AI Introduction: The Emergence of Agentic AI Recent advancements in libraries and low-code platforms have simplified the creation of AI agents, often referred to as digital workers. Tool calling stands out as a key capability that enhances the “agentic” nature of Generative AI models, enabling them to move beyond mere conversational tasks. By executing tools (functions), these agents can act on your behalf and tackle intricate, multi-step problems requiring sound decision-making and interaction with diverse external data sources. This insight explores the role of reasoning in tool calling, examines the challenges associated with tool usage, discusses common evaluation methods for tool-calling proficiency, and provides examples of how various models and agents engage with tools. Reasoning as a Means of Problem-Solving Successful agents rely on two fundamental expressions of reasoning: reasoning through evaluation and planning, and reasoning through tool use. While both reasoning expressions are vital, they don’t always need to be combined to yield powerful solutions. For instance, OpenAI’s new o1 model excels in reasoning through evaluation and planning, having been trained to utilize chain of thought effectively. This has notably enhanced its ability to address complex challenges, achieving human PhD-level accuracy on benchmarks like GPQA across physics, biology, and chemistry, and ranking in the 86th-93rd percentile on Codeforces contests. However, the o1 model currently lacks explicit tool calling capabilities. Conversely, many models are specifically fine-tuned for reasoning through tool use, allowing them to generate function calls and interact with APIs effectively. These models focus on executing the right tool at the right moment but may not evaluate their results as thoroughly as the o1 model. The Berkeley Function Calling Leaderboard (BFCL) serves as an excellent resource for comparing the performance of various models on tool-calling tasks and provides an evaluation suite for assessing fine-tuned models against challenging scenarios. The recently released BFCL v3 now includes multi-step, multi-turn function calling, raising the standards for tool-based reasoning tasks. Both reasoning types are powerful in their own right, and their combination holds the potential to develop agents that can effectively deconstruct complex tasks and autonomously interact with their environments. For more insights into AI agent architectures for reasoning, planning, and tool calling, check out my team’s survey paper on ArXiv. Challenges in Tool Calling: Navigating Complex Agent Behaviors Creating robust and reliable agents necessitates overcoming various challenges. In tackling complex problems, an agent often must juggle multiple tasks simultaneously, including planning, timely tool interactions, accurate formatting of tool calls, retaining outputs from prior steps, avoiding repetitive loops, and adhering to guidelines to safeguard the system against jailbreaks and prompt injections. Such demands can easily overwhelm a single agent, leading to a trend where what appears to an end user as a single agent is actually a coordinated effort of multiple agents and prompts working in unison to divide and conquer the task. This division enables tasks to be segmented and addressed concurrently by distinct models and agents, each tailored to tackle specific components of the problem. This is where models with exceptional tool-calling capabilities come into play. While tool calling is a potent method for empowering productive agents, it introduces its own set of challenges. Agents must grasp the available tools, choose the appropriate one from a potentially similar set, accurately format the inputs, execute calls in the correct sequence, and potentially integrate feedback or instructions from other agents or humans. Many models are fine-tuned specifically for tool calling, allowing them to specialize in selecting functions accurately at the right time. Key considerations when fine-tuning a model for tool calling include: Common Benchmarks for Evaluating Tool Calling As tool usage in language models becomes increasingly significant, numerous datasets have emerged to facilitate the evaluation and enhancement of model tool-calling capabilities. Two prominent benchmarks include the Berkeley Function Calling Leaderboard and the Nexus Function Calling Benchmark, both utilized by Meta to assess the performance of their Llama 3.1 model series. The recent ToolACE paper illustrates how agents can generate a diverse dataset for fine-tuning and evaluating model tool use. Here’s a closer look at each benchmark: Each of these benchmarks enhances our ability to evaluate model reasoning through tool calling. They reflect a growing trend toward developing specialized models for specific tasks and extending the capabilities of LLMs to interact with the real world. Practical Applications of Tool Calling If you’re interested in observing tool calling in action, here are some examples to consider, categorized by ease of use, from simple built-in tools to utilizing fine-tuned models and agents with tool-calling capabilities. While the built-in web search feature is convenient, most applications require defining custom tools that can be integrated into your model workflows. This leads us to the next complexity level. To observe how models articulate tool calls, you can use the Databricks Playground. For example, select the Llama 3.1 405B model and grant access to sample tools like get_distance_between_locations and get_current_weather. When prompted with, “I am going on a trip from LA to New York. How far are these two cities? And what’s the weather like in New York? I want to be prepared for when I get there,” the model will decide which tools to call and what parameters to provide for an effective response. In this scenario, the model suggests two tool calls. Since the model cannot execute the tools, the user must input a sample result to simulate. Suppose you employ a model fine-tuned on the Berkeley Function Calling Leaderboard dataset. When prompted, “How many times has the word ‘freedom’ appeared in the entire works of Shakespeare?” the model will successfully retrieve and return the answer, executing the required tool calls without the user needing to define any input or manage the output format. Such models handle multi-turn interactions adeptly, processing past user messages, managing context, and generating coherent, task-specific outputs. As AI agents evolve to encompass advanced reasoning and problem-solving capabilities, they will become increasingly adept at managing