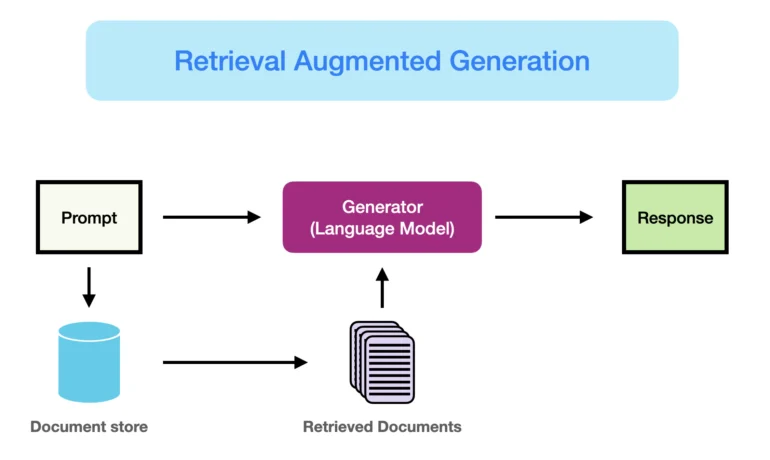
Generative AI Prompts with Retrieval Augmented Generation
By now, you’ve likely experimented with generative AI language models (LLMs) such as OpenAI’s ChatGPT or Google’s Gemini to aid in composing emails or crafting social media content. Yet, achieving optimal results can be challenging—particularly if you haven’t mastered the art and science of formulating effective prompts. Generative AI Prompts with Retrieval Augmented Generation. The effectiveness of an AI model hinges on its training data. To excel, it requires precise context and substantial factual information, rather than generic details. This is where Retrieval Augmented Generation (RAG) comes into play, enabling you to seamlessly integrate your most current and pertinent proprietary data directly into your LLM prompt. Here’s a closer look at how RAG operates and the benefits it can offer your business. Generative AI Prompts with Retrieval Augmented Generation Why RAG Matters: An AI model’s efficacy is determined by the quality of its training data. For optimal performance, it needs specific context and substantial factual information, not just generic data. An off-the-shelf LLM lacks the real-time updates and trustworthy access to proprietary data essential for precise responses. RAG addresses this gap by embedding up-to-date and pertinent proprietary data directly into LLM prompts, enhancing response accuracy. How RAG Works: RAG leverages powerful semantic search technologies within Salesforce to retrieve relevant information from internal data sources like emails, documents, and customer records. This retrieved data is then fed into a generative AI model (such as CodeT5 or Einstein Language), which uses its language understanding capabilities to craft a tailored response based on the retrieved facts and the specific context of the user’s query or task. Case Study: Algo Communications In 2023, Canada-based Algo Communications faced the challenge of rapidly onboarding customer service representatives (CSRs) to support its growth. Seeking a robust solution, the company turned to generative AI, adopting an LLM enhanced with RAG for training CSRs to accurately respond to complex customer inquiries. Algo integrated extensive unstructured data, including chat logs and email history, into its vector database, enhancing the effectiveness of RAG. Within just two months of adopting RAG, Algo’s CSRs exhibited greater confidence and efficiency in addressing inquiries, resulting in a 67% faster resolution of cases. Key Benefits of RAG for Algo Communications: Efficiency Improvement: RAG enabled CSRs to complete cases more quickly, allowing them to address new inquiries at an accelerated pace. Enhanced Onboarding: RAG reduced onboarding time by half, facilitating Algo’s rapid growth trajectory. Brand Consistency: RAG empowered CSRs to maintain the company’s brand identity and ethos while providing AI-assisted responses. Human-Centric Customer Interactions: RAG freed up CSRs to focus on adding a human touch to customer interactions, improving overall service quality and customer satisfaction. Retrieval Augmented Generation (RAG) enhances the capabilities of generative AI models by integrating current and relevant proprietary data directly into LLM prompts, resulting in more accurate and tailored responses. This technology not only improves efficiency and onboarding but also enables organizations to maintain brand consistency and deliver exceptional customer experiences. Like Related Posts Salesforce OEM AppExchange Expanding its reach beyond CRM, Salesforce.com has launched a new service called AppExchange OEM Edition, aimed at non-CRM service providers. Read more The Salesforce Story In Marc Benioff’s own words How did salesforce.com grow from a start up in a rented apartment into the world’s Read more Salesforce Jigsaw Salesforce.com, a prominent figure in cloud computing, has finalized a deal to acquire Jigsaw, a wiki-style business contact database, for Read more Service Cloud with AI-Driven Intelligence Salesforce Enhances Service Cloud with AI-Driven Intelligence Engine Data science and analytics are rapidly becoming standard features in enterprise applications, Read more