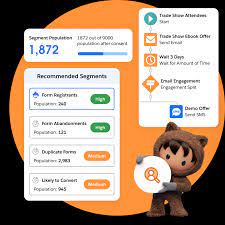
Rebranding initiatives are a powerful tool for companies to continuously enhance their products, showcasing a commitment to ongoing innovation and improvement. Salesforce, a leader in this arena, has recently undergone a significant transformation, particularly with the rebranding of its Marketing Cloud to Marketing Cloud Engagement. Understanding these changes is crucial for businesses, and Tectonic, as a trusted expert, is here to provide insights. With many of their products being like ‘the artist formerly known as’ it can be hard to keep them all straight. These transformations can be abrupt for users who have deeply integrated entire platforms into their mission-critical operations. Announcing Marketing Cloud Engagement. Formerly Salesforce Marketing Cloud. Most of us are still trying to quit calling Marketing Cloud Account Engagement Pardot. Pardot and Marketing Cloud have been two leading Salesforce marketing automation tools since 2013. By 2022, more than 37,000 companies had integrated Pardot with Salesforce, and over 22,000 businesses had used or were using Marketing Cloud, according to statistics from Infoclutch.com and Enlyft.com. With the recent rebranding of Salesforce Marketing Cloud, Salesforce aims to support organizations utilizing Salesforce by offering insights. Our experts at Tectonic are here to help. Tectonic’s goal is to help you comprehend the implications of these changes for your company. Whether your organization operates in the public sector, hospitality, transportation, health, life sciences, financial services, or the nonprofit sector, comprehending the distinctions between Marketing Cloud and Marketing Cloud Account Engagement (formerly Pardot) is essential for making informed decisions that align with your goals. Marketing Cloud Engagement Build relationships with engagement marketing tools, powered by AI. Einstein AI partnered with Marketing Cloud Engagement enable you to do more, smarter, and faster. Activate your data in real-time to deliver personalized campaigns and engagement at scale and increase your customer lifetime value. Let’s address key questions about the Salesforce Marketing Cloud name change: For organizations aiming to optimize engagement efforts, a thorough understanding of these products is necessary to maximize investments and enhance customer and constituent impact. Whether your company has a long history with Salesforce or recently adopted it, the answers to these questions will aid your organization in maximizing the potential of your CRM. Announcing Marketing Cloud Engagement Marketing Cloud Engagement (formerly known as Marketing Cloud) is a business-to-consumer (B2C) marketing automation platform with multiple modules, providing a unified interface. This enables organizations to streamline, target, and personalize messages to stakeholders, members, and other audiences, ensuring maximum return on investment. Companies seeking personalized communication and community experiences should consider Marketing Cloud Engagement. It provides built-in tools like email templates, driven by AI-powered Einstein, to deliver personalized campaigns at scale. Real-time data activation enhances engagement, and its modular structure allows for tailored solutions. Tailored for marketing campaigns dealing with large data volumes, Marketing Cloud has a robust product architecture situated on its own platform, distinct from the core Salesforce infrastructure. It employs connectors like Marketing Cloud Connect for integration. The module structure sets Marketing Cloud apart, with Studios managing content and marketing channels (e.g., Web Studio, Mobile Studio) and Builders overseeing data and campaign automation (Content Builder, Audience Builder, Contact Builder). These modules collaborate across marketing channels for various applications such as email marketing, SMS, push notifications, targeted online advertising, data management, customer journeys, and more. How can you use Marketing Cloud? Companies looking to personalize campaign communication and community experiences should consider Marketing Cloud Engagement, possibly with Salesforce Experience Cloud. Reporting functionalities offer visualizations consolidating performance data from various marketing channels, allowing teams to assess campaign success and adjust strategies based on results. Quick ways to determine if Marketing Cloud Engagement is suitable for your team include valuing personalization, having shorter decision-making cycles, dealing with large amounts of data from multiple sources, needing to segment contacts outside the core Salesforce platform, and having the resources for in-house training or hiring a Marketing Cloud consultant. Budget considerations are also vital, as Marketing Cloud comes with a higher price tag and additional training costs. Bring It All Together? Have you ever wondered why sales and marketing teams combine Salesforce Marketing Cloud Engagement and Account Engagement (formerly Pardot), with Sales Cloud to reach their goals? Thinking about how these platforms can work together likely makes your head spin like a twister in Kansas. But, combined the suite makes for a sweet sales and marketing tool box. How Salesforce Marketing Automation Can Help Your Business? Salesforce marketing automation enhances campaign management and operational efficiency across various channels, offering: Effective implementation of marketing automation can significantly increase lead conversion rates, with 77% of businesses reporting growth after adoption. It also enables staff to automate routine tasks, reduces errors, and supports business expansion and adaptability. What is Marketing Cloud Account Engagement (formerly Pardot)? Marketing Cloud Account Engagement (MCAE) integrates closely with your CRM, operating partially on the core Salesforce infrastructure and partially on its infrastructure. Ideal for business-to-business (B2B) scenarios and “considered purchases,” MCAE excels in longer sales cycles and outreach campaigns. It offers functionalities like prospect behavior monitoring, Salesforce object connection, lead generation, email nurture campaigns, content and webinar marketing, and account-based marketing (ABM). MCAE excels in business-to-business (B2B) scenarios and “considered purchases” involving more decision-makers and longer sales cycles. MCAE simplifies marketing strategies by automatically pulling CRM data for personalized experiences. It fosters cross-departmental collaboration, qualifies leads, automates campaigns, transforms user behavior data into actionable insights, and utilizes AI for prospect identification. Why did Pardot’s name change? Salesforce rebranded to streamline the software purchasing process for customers, aiming for a more consistent experience. This initiative addresses gaps in customer knowledge about their products. Is Marketing Cloud Account Engagement part of Marketing Cloud? While the rebrand unifies Marketing Cloud and Marketing Cloud Account Engagement under the same product suite, MCAE retains an intentionally independent product architecture. This differentiation extends beyond functionality and involves deliberate architecture decisions in resource locations and infrastructure designs. MCAE focuses on unifying sales and marketing and sources less data than Marketing Cloud Engagement. Consequently, MCAE can exist partially on its architecture and partially on