Once Upon a Time in Data Land
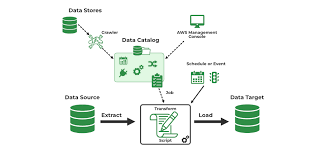
Once Upon a Time in Data Land: Building the Artificial Intelligence-Ready Warehouse In the early days of data, businesses simply wanted to know what had already happened in the past. Questions like “How many units shipped?” or “What were last month’s sales?” drove the first major digital settlements—the Digitally Filed Data Warehouse. Looking back this seems like the aluminum carport you can have erected in your driveway. The Meticulously Organized Library (The Digitally Filed Data Warehouse Era) Imagine a grand, meticulously organized library. Data from sales, finance, and inventory wasn’t just dumped inside—it went through ETL (Extract, Transform, Load), where it was cleaned, standardized, and structured into predefined formats. Need quarterly sales figures? They were always in the same place, ready for reliable reporting. But then, the world outside got messy. Suddenly, businesses weren’t just dealing with neat rows and columns—they faced website clicks, customer emails, sensor data, social media streams, images, and videos. The rigid Digitally Filed Data Warehouse struggled to adapt. Trying to force unstructured data through ETL was like trying to shelve a waterfall—slow, expensive, and often impossible. The Everything Shed (The Rise of the AI-Powered Warehouse) Enter the AI-Powered Warehouse—a vast, flexible storage space built for raw, unstructured data. Instead of forcing structure upfront, it embraced “store first, organize later” (schema-on-read). Data scientists could explore everything, from tweets to video transcripts, without constraints. But freedom had a cost. Without governance, many AI-Powered Warehouses became “data swamps”—cluttered, unreliable, and slow. Finding clean, trustworthy data was a treasure hunt, and building reliable AI pipelines was a challenge. Organizing the Shed (The AI-Ready Warehouse Paradigm) The solution? Structure without sacrifice. The AI-Ready Warehouse kept the flexibility of raw storage but added intelligence on top. Technologies like Delta Lake, Apache Iceberg, and Apache Hudi introduced:✔ ACID transactions (no more corrupted data)✔ Data versioning (“time travel” to past states)✔ Schema enforcement (order without rigidity)✔ Performance optimizations (speed at scale) A key innovation was the Medallion Architecture, organizing data by quality: This hybrid approach unified BI dashboards, analytics, and machine learning—all on the same foundation. The AI Factory (The Modern AI-Functioning Warehouse) Just as businesses adapted, AI evolved. Generative AI, autonomous agents, and real-time decision-making demanded more than batch-processed data. The AI-Ready Warehouse transformed into a fully integrated AI factory, built for: 🔹 Real-Time & Streaming Data 🔹 Seamless MLOps Integration 🔹 Vector Databases & Embeddings 🔹 Robust AI Governance Why This Matters for AI Agents Autonomous AI agents don’t just analyze data—they act on it. The AI-Functioning Warehouse gives them:✔ Context: Real-time data + historical insights✔ Consistency: Features match training data✔ Memory: Logged actions for continuous learning The Future: An AI-Native Data Ecosystem The journey from Digitally Filed Data Warehouse to AI-Powered Warehouse to AI-Functioning Warehouse reflects a shift from static reporting to dynamic intelligence. For businesses embracing AI, the question is no longer “Do we need a data strategy?” but “Is our data foundation AI-ready?” The answer will separate the leaders from the laggards in the age of AI. Next Steps: The future belongs to those who build not just for data, but for AI. Like Related Posts Salesforce OEM AppExchange Expanding its reach beyond CRM, Salesforce.com has launched a new service called AppExchange OEM Edition, aimed at non-CRM service providers. Read more The Salesforce Story In Marc Benioff’s own words How did salesforce.com grow from a start up in a rented apartment into the world’s Read more Salesforce Jigsaw Salesforce.com, a prominent figure in cloud computing, has finalized a deal to acquire Jigsaw, a wiki-style business contact database, for Read more Service Cloud with AI-Driven Intelligence Salesforce Enhances Service Cloud with AI-Driven Intelligence Engine Data science and analytics are rapidly becoming standard features in enterprise applications, Read more