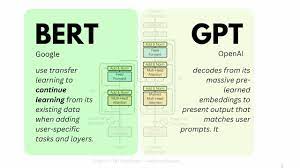
Einstein Code Generation and Amazon SageMaker
Salesforce and the Evolution of AI-Driven CRM Solutions Salesforce, Inc., headquartered in San Francisco, California, is a leading American cloud-based software company specializing in customer relationship management (CRM) software and applications. Their offerings include sales, customer service, marketing automation, e-commerce, analytics, and application development. Salesforce is at the forefront of integrating artificial general intelligence (AGI) into its services, enhancing its flagship SaaS CRM platform with predictive and generative AI capabilities and advanced automation features. Einstein Code Generation and Amazon SageMaker. Salesforce Einstein: Pioneering AI in Business Applications Salesforce Einstein represents a suite of AI technologies embedded within Salesforce’s Customer Success Platform, designed to enhance productivity and client engagement. With over 60 features available across different pricing tiers, Einstein’s capabilities are categorized into machine learning (ML), natural language processing (NLP), computer vision, and automatic speech recognition. These tools empower businesses to deliver personalized and predictive customer experiences across various functions, such as sales and customer service. Key components include out-of-the-box AI features like sales email generation in Sales Cloud and service replies in Service Cloud, along with tools like Copilot, Prompt, and Model Builder within Einstein 1 Studio for custom AI development. The Salesforce Einstein AI Platform Team: Enhancing AI Capabilities The Salesforce Einstein AI Platform team is responsible for the ongoing development and enhancement of Einstein’s AI applications. They focus on advancing large language models (LLMs) to support a wide range of business applications, aiming to provide cutting-edge NLP capabilities. By partnering with leading technology providers and leveraging open-source communities and cloud services like AWS, the team ensures Salesforce customers have access to the latest AI technologies. Optimizing LLM Performance with Amazon SageMaker In early 2023, the Einstein team sought a solution to host CodeGen, Salesforce’s in-house open-source LLM for code understanding and generation. CodeGen enables translation from natural language to programming languages like Python and is particularly tuned for the Apex programming language, integral to Salesforce’s CRM functionality. The team required a hosting solution that could handle a high volume of inference requests and multiple concurrent sessions while meeting strict throughput and latency requirements for their EinsteinGPT for Developers tool, which aids in code generation and review. After evaluating various hosting solutions, the team selected Amazon SageMaker for its robust GPU access, scalability, flexibility, and performance optimization features. SageMaker’s specialized deep learning containers (DLCs), including the Large Model Inference (LMI) containers, provided a comprehensive solution for efficient LLM hosting and deployment. Key features included advanced batching strategies, efficient request routing, and access to high-end GPUs, which significantly enhanced the model’s performance. Key Achievements and Learnings Einstein Code Generation and Amazon SageMaker The integration of SageMaker resulted in a dramatic improvement in the performance of the CodeGen model, boosting throughput by over 6,500% and reducing latency significantly. The use of SageMaker’s tools and resources enabled the team to optimize their models, streamline deployment, and effectively manage resource use, setting a benchmark for future projects. Conclusion and Future Directions Salesforce’s experience with SageMaker highlights the critical importance of leveraging advanced tools and strategies in AI model optimization. The successful collaboration underscores the need for continuous innovation and adaptation in AI technologies, ensuring that Salesforce remains at the cutting edge of CRM solutions. For those interested in deploying their LLMs on SageMaker, Salesforce’s experience serves as a valuable case study, demonstrating the platform’s capabilities in enhancing AI performance and scalability. To begin hosting your own LLMs on SageMaker, consider exploring their detailed guides and resources. Like Related Posts Salesforce OEM AppExchange Expanding its reach beyond CRM, Salesforce.com has launched a new service called AppExchange OEM Edition, aimed at non-CRM service providers. Read more The Salesforce Story In Marc Benioff’s own words How did salesforce.com grow from a start up in a rented apartment into the world’s Read more Salesforce Jigsaw Salesforce.com, a prominent figure in cloud computing, has finalized a deal to acquire Jigsaw, a wiki-style business contact database, for Read more Service Cloud with AI-Driven Intelligence Salesforce Enhances Service Cloud with AI-Driven Intelligence Engine Data science and analytics are rapidly becoming standard features in enterprise applications, Read more