
Can BigQuery Function as a Data Lake? Why you should Bring Your Own Lake With Google BigQuery.
Google BigQuery serves as a fully-managed, petabyte-scale data warehouse, utilizing Google’s infrastructure’s processing power. The combination of Google Cloud Storage and BigQuery transforms Google Cloud Platform into a scalable data lake capable of storing both structured and unstructured data.
Why Embrace BigQuery’s Serverless Model?
In a serverless model, processing is automatically distributed across numerous machines operating in parallel. BigQuery’s serverless model allows data engineers and database administrators to concentrate less on infrastructure and more on server provisioning and deriving insights from data.
Advantages of Using BigQuery as a Data Warehouse:
BigQuery is a completely serverless and cost-effective cloud data warehouse designed to work across clouds, scaling seamlessly with your data. With integrated business intelligence, machine learning, and AI features, BigQuery provides a unified data platform for storing, analyzing, and sharing insights effortlessly.
The Relevance of Data Lakes:
Data Lakes and Data Warehouses are complementary components of data processing and reporting infrastructure, each serving distinct purposes rather than being alternatives.
Data Lakes in the Evolving Landscape:
Data lakes, once immensely popular, are gradually being supplanted by more advanced storage solutions like data warehouses.
Data Lake Content Formats:
A data lake encompasses structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs), and binary data (images, audio, video).
Building a Data Lake on GCP:
- Create a BigQuery Dataset and Table: Access the GCP Console, select BigQuery, and generate a new dataset with a unique name and preferred storage location. Then, create a table within the BigQuery dataset to store data from Cloud Storage.
Constructing a Data Lake:
- Set up storage.
- Transfer data.
- Cleanse, prepare, and catalog data.
- Configure and enforce security and compliance policies.
- Make data available for analytics.
Introduction to Google Big Lake:
BigLake serves as a storage engine, offering a unified interface for analytics and AI engines to query multiformat, multicloud, and multimodal data securely, efficiently, and in a governed manner. It aspires to create a single-copy AI lakehouse, minimizing the need for custom data infrastructure management.
Data Extraction from a Data Lake:
- Choose tools suited for data extraction from your specific data lake, such as Apache Spark, Apache Flink, Apache Hive, AWS Glue, Azure Data Factory, or Google Cloud Dataflow.
- Craft efficient SQL queries to extract necessary columns and rows.
Distinguishing BigQuery as a Data Warehouse:
BigQuery stands out as a serverless and cost-effective enterprise data warehouse, functioning across clouds and seamlessly scaling with data. It incorporates built-in ML/AI and BI for scalable insights.
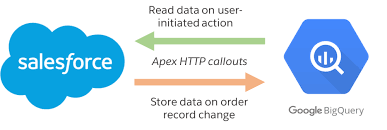
Data Lake Implementation Time:
Building a fully productive data lake involves several steps, including workflow creation, security mapping, and tool and service configuration. As a result, a comprehensive data lake implementation can take several months.
Acquiring a Data Lake:
One option is to buy a Data Lake through a decentralized exchange (DEX) supporting the blockchain where the Data Lake resides. Connecting a crypto wallet to a DEX and utilizing a Binance account to purchase the base currency is outlined in a guide for this purpose.
To ensure the proper sequencing of Tags, modify the Tag sequencing in the Google Analytics preview Tag settings. The custom Read more
This tag stores data in both the page referrer and URL parameters within a browser cookie. This cookie proves useful, Read more
Snowflake has deepened its partnership with investor Salesforce by introducing two tools that seamlessly connect their cloud-native systems. Snowflake and Read more

What Are UTM Parameters in Marketing Cloud? UTM parameters are essential for tracking the effectiveness of your marketing messages by Read more







